Разделы
Счетчики
Семантические сети
Семантическая сеть - структура для представления знаний в виде узлов, соединенных дугами. Самые первые семантические сети были разработаны в качестве языка-посредника для систем машинного перевода, а многие современные версии до сих пор сходны по своим характеристикам с естественным языком. Однако последние версии семантических сетей стали более мощными и гибкими и составляют конкуренцию фреймовым системам, логическому программированию и другим языкам представления знаний.
Начиная с конца 50-ых годов прошлого века были созданы и применены на практике десятки вариантов семантических сетей. Несмотря на то, что терминология и их структура различаются, существуют сходства, присущие практически всем семантическим сетям:
1. Узлы семантических сетей представляют собой концепты предметов, событий, состояний.
2. Различные узлы одного концепта относятся к различным значениям, если для них не помечено, что они относятся к одному концепту.
3. Дуги семантических сетей создают отношения между узлами-концептами (пометки над дугами указывают на тип отношения).
4. Некоторые отношения между концептами представляют собой лингвистические падежи, такие как агент, объект, реципиент и инструмент (другие означают временные, пространственные, логические отношения и отношения между отдельными предложениями).
5. Концепты организованы по уровням в соответствии со степенью обобщенности. Как пример, сущность, живое существо, животное, плотоядное.
Однако существуют и различия: понятие значения с точки зрения философии; методы представления кванторов общности и существования и логических операторов; способы манипулирования сетями и правила вывода, терминология. Все это варьируется от автора к автору. Несмотря не некоторые различия, сети удобны для чтения и обработки компьютером, а также достаточно мощны, чтобы представить семантику естественного языка.
Историческая справка
Фрег представил логические формулы в виде деревьев, которые однако мало напоминают современные семантические сети. Еще одним пионером стал Чарльз Сандерз Прис, который использовал графические записи в органической химии. Он сформулировал правила вывода с использованием экзистенциональных графов. В психологии Зельц использовал графы для представления наследственности некоторых характеристик в иерархии концептов. Научные изыскания Зельца имели огромное влияние на изучение тактики в шахматах, и Зельц в свою очередь повлиял на таких теоретиков как Саймон и Ньюэлл.
Что касается лингвистики, то первым ученым, занимавшимся разработкой графических описаний, стал Теньер. Он использовал графическую запись для своей грамматики зависимостей. Теньер оказал огромное влияние на развитие лингвистики в Европе.
Впервые семантические сети были использованы в системах машинного перевода в конце 50-х - начале 60-х годов прошлого века. Первая такая система, которую создала Мастерман, включала в себя 100 примитивных концептов как, например, НАРОД, ВЕЩЬ, ДЕЛАТЬ, БЫТЬ. С помощью этих концептов она описала словарь объемом 15000 единиц, в котором также имелся механизм переноса характеристик с гипертипа на подтип. Некоторые системы машинного перевода базировались на корреляционных сетях Цеккато, которые представляли собой набор 56 различных отношений, некоторые из которых - падежные отношения, отношения подтипа, члена, части и целого. Цекатто использовал сети, состоящие из концептов и отношений для руководства действиями парсера (parser - синтаксического анализатора) и разрешения неоднозначностей.
В системах искусственного интеллекта семантические сети используются для ответа на различные вопросы, изучения процессов обучения, запоминания и рассуждений. В конце 70-х сети получили широкое распространение. В 80-х годах границы между сетями, фреймовыми структурами и линейными формами записи постепенно стирались. Выразительная сила больше не является решающим аргументом в пользу выбора сетей или линейных форм записи, поскольку идеи, записанные с помощью одной формы записи, могут быть легко переведены в другую. И наоборот, особую значимость получили второстепенные факторы, такие как читаемость, эффективность, естественность и теоретическая элегантность, причем также учитываются легкость введения в компьютер, редактирование и распечатка.
Реляционные графы
Самые простые сети, которые используются в системах искусственного интеллекта, - это реляционные графы. Они состоят из узлов, соединенных дугами. Каждый узел представляет собой понятие, а каждая дуга - отношения между различными понятиями. Ниже представлено предложение "Собака жадно гложет кость". Четыре прямоугольника представляют понятия самой собаки, процесса глодания кости, самой кости и такой характеристики как жадность. Надписи рядом с дугами означают, что собака является агентом процесса, кость является объектом этого процесса, а жадность - это характеристика выполнения процесса.
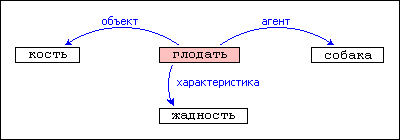
Терминология, использующаяся в этой области, различна. Чтобы добиться некоторой однородности, узлы, соединенные дугами, принято называть графами, а структуру, где имеется целое гнездо из узлов или где существуют отношения различного порядка между графами, называть сетью. Помимо терминологии, использующейся для пояснения, также различаются способы изображения. Некоторые используют кружки вместо прямоугольников; некоторые пишут типы отношений над или под дугами, заключая или же не заключая их в овалы; некоторые используют аббревиатуры вида О или А для обозначения агента или объекта; некоторые используют различные типы стрелок.
Поскольку довольно сложно ввести в компьютер некоторые диаграммы и при этом они занимают много места при печати, многие ученые записывают свои графы в более компактном варианте. Например, то же предложение о собаке Сова предложил записать в линейном виде с использованием некоторых символьных подобий в отношении элементов приведенного рисунка:
[глодать]-
(агент) -> [собака]
(объект) -> [кость]
(характеристика) -> [жадность]В этом варианте записи квадратные скобки обозначают понятия, а круглые скобки содержат в себе названия отношений. Все линейные формы записи очень похожи на фреймовые структуры.
Графы с центром в глаголе
Глаголы соединяются с группой существительного с использованием падежных отношений. Например, в предложении "Маша дала книгу Феде" Маша выступает агентом процесса "дать", книга выступает объектом этого процесса, а Федя становится получателем обслуживаемого процессом объекта. Подобное отнесение участников предложения к процессуальным категориям становится ясно из падежных окончаний вкупе с глаголом, обозначающим выполняемый процесс.
Помимо падежных отношений в предложении в естественном языке также имеются средства для связи отдельных предложений. Такие связи осуществляются следующими элементами языка.
Союзы. Самый простой способ соединить предложения - это поставить между ними союз. Некоторые союзы, как например "и", "или", "если" обозначают логическую связь; некоторые, такие как "после того, как", "когда", "пока", "с тех пор, как" и "потому что", выражают временные отношения и причину.
Глаголы, требующие подчиненное предложение. Падежные фреймы многих глаголов требуют подчиненного предложения, являющегося обычно прямым дополнением. К такому типу относятся глаголы "говорить", "считать", "думать", "знать", "быть убежденным", "угрожать", "пытаться" и другие.
Определители, относящиеся к целому предложению. Многие наречия и пропозиционные фразы относятся только к глаголу, но некоторые определяют целое предложение. Такие наречия как "обычно", "вероятно" в большинстве случаев ставятся в начале предложения. А например, слово "однажды" определяет весь рассказ, следующий после него.
Модальные глаголы и времена. Такие глаголы как "может", "должен" и им подобные имеют модальное значение и относятся ко всему предложению, где они встречаются. Временное отношение может быть выражено как формой прошедшего времени глаголов, так и обстоятельствами "сейчас", "завтра" или "однажды" и другими.
Связанный дискурс (пересечение). Помимо отношений, выраженных в одном предложении, существуют также отношения более высокого порядка между отдельными предложениями рассказа или какого-либо другого повествования. Многие из них не выражены эксплицитно: временные отношения и следование аргументов может быть, например, имплицитно выражено порядком следования предложения друг за другом в тексте.
Именно потому, что глаголу отводится такая важная роль в предложении, многие теории делают его своим центральным связующим звеном. Этот подход берет свое начало из Индо-Европейской языковой семьи, где модальность и временные отношения выражаются изменением глагольной формы. Рассмотрим следующий пример: "Пока собака грызет кость, кот остается незамеченным". В этом предложении сообщено, что когда утверждение "пока собака грызет кость" является истинным, второе утверждение "кот остается незамеченным" также является истинным.
Так вот для подобных предложений необходимо строить узлы с центром в глаголе, и такие узлы - это реляционные графы, где глагол считается центральным звеном любого предложения. Маркеры времени и отношения пишутся прямо рядом с концептами, которые представляют глаголы.
Несмотря на то, что графы с центром в глаголе довольно гибкие по своей структуре, они обладают рядом ограничений. Одно из них заключается в том, что они не проводят разграничение между определителями, которые относятся только к глаголу, и определителями, относящимися к предложению целиком. Рассмотрим следующие примеры: "Собака жадно грызет кость" и "Жадно, но собака грызет кость". Графы с центром в глаголе также плохо справляются с элементами, находящимися внутри других предложений. Во втором примере предложение составлено из двух частей, объединенных союзом "но".
При работе с реляционными графами возникают проблемы с передачей всего многообразия временных отношений и отношений модальности. Несмотря на то, что многие учение используют эти графы для решения сложных проблем, они так до сих пор и не разработали общего метода для их разрешения.
Пропозиционные сети
В пропозиционных сетях узлы представляют целые предложения. Эти узлы являются точками соприкосновения для отношений между отдельными предложениями связанного текста. С другой стороны они определяют время и модальность для всего контекста. Следующие примеры иллюстрируют отношения, для записи которых необходимы пропозиционные узлы: "Света думает, что Боря полагает, будто собака грызет кость" или "Если собака грызет кость, неразумно пытаться забрать ее у нее".
В первом предложении для глаголов "думать" и "полагать" целое предложение является дополнением: Боря полагает, что "собака грызет кость". Мысль Светы представляет собой более сложное предложение: "Боря полагает, будто собака грызет кость". Такое гнездование предложений внутри других предложений может повторяться сколь угодно большое количество раз. Чтобы изобразить такое предложение, необходимо использовать пропозиционные узлы, которые содержат гнездящиеся графы.
Во втором примере представлены два предложения, находящиеся в отношении условия. Антецедентом является предложение "собака грызет кость", а консеквентом - предложение "неразумно пытаться забрать ее у нее". Инфинитивы "пытаться" и "забрать" указывают на другие гнездящиеся предложения. Причем для этого предложения также необходимо указать соответствие между "ее", "нее" и "кость", "собака". Для формальной записи такого предложения также используются кванторы общности и существования и некоторые элементы логики.
Все реляционные графы и графы с центром в глаголе имеют много общего. Однако среди них существуют также и отличия:
1. Включение контекста или всего лишь его условное обозначение с отсылкой на схеме.
2. Строгое гнездование: один и тот же концепт может или не может встречаться в двух разных контекстах, ни один из которых не гнездится в другом.
3. Указание связей соответствия. При перекрещивающемся контексте, то есть когда один и тот же концепт встречается в двух разных контекстах, эти связи не указываются.
Однако это всего лишь стилистические расхождения, которые не влияют существенно на логику построения.
Иерархия типов
Иерархия типов и подтипов является стандартной характеристикой семантических сетей. Иерархия может включать длинную цепочку сущностей: такса<собака<плотоядное<животное<живое существо<физический объект<сущность. Затронутые сущности также могут включать в себя пути к процессам: жертвовать<давать<действие<событие или пути к характеристикам: экстаз<счастье<эмоциональное состояние<состояние. Иерархия Аристотеля включала в себя 10 основных категорий: субстанция, количество, качество, отношение, место, время, состояние, активность и пассивность. Некоторые учения дополнили его своими категориями.
Символ < между более общим и более частным элементом читается как: "Х-тип/подтип У". Термин "иерархия" обычно обозначает частичное упорядочение, где одни типы являются более общими, чем другие. Упорядочение является частичным, потому что многие типы просто не подлежат сравнению между собой. Сравним: "дом<собака" и "собака<дом" бессмысленны, если их сравнивать, однако слово Собака.Дом является подтипом Дом, но не Собака. Рассмотрим некоторые виды графов.
Ацикличный граф. Любое частичное упорядочение может быть изображено как граф без циклов. Такой граф имеет ветви, которые расходятся и сходятся вместе опять, что позволяет некоторым узлам иметь несколько узлов-родителей. Иногда такой тип графа называют путанным.
Деревья. Самым распространенным видом иерархии является граф с одной вершиной. В такого рода графах налагаются ограничения на ацикличные графы: вершина графа представляет собой один общий тип, и каждый другой тип Х имеет лишь одного родителя У.
Решетка. В отличие от деревьев узлы в решетке могут иметь несколько узлов родителей. Однако здесь налагаются другие ограничения: любая пара типов Х и У как минимум должна иметь общий гипертип "Х и У" и подтип "Х или У". По этой причине решетка выглядит как дерево, имеющее по главной вершине с каждого конца. Вместо всего одной вершины решетка имеет одну вершину, которая является гипертипом всех категорий, и другую вершину, которая является подтипом всех типов.
Наследование
Основным свойством иерархии является возможность наследования подтипами качеств гипертипов: все характеристики, которые присущи ЖИВОТНОМУ, также присущи МЛЕКОПИТАЮЩЕМУ, РЫБЕ и ПТИЦЕ. В основе теории наследования лежит теория силлогизмов Аристотеля: "если А - характеристика В, а В - характеристика С, то А - характеристика всех С".
Преимущества иерархии и наследования: иерархия типов является отличной структурой для индексирования базы знаний и ее эффективной организации; следование по какой-либо ветви с помощью иерархии осуществляется гораздо быстрее.
Синтаксический анализ языка и его порождение
Семантические сети могут помочь парсеру разрешить семантическую неоднозначность. Без такого рода представления вся тяжесть анализа языка падает на синтаксические правила и семантические тесты. Структура же семантической сети ясно показывает, как отдельные концепты соединены между собой. Когда парсер встречает какую-либо неоднозначность, он может использовать семантическую сеть для того, чтобы выбрать тот или иной вариант. При работе с семантическими сетями используется несколько техник парсинга.
Парсинг, в основе которого лежит синтаксис. Работа парсера контролируется грамматикой непосредственных составляющих и операторами построения структур и их тестирования. В то время как данные на входе анализируются, операторы построения структур создают семантическую сеть, а операторы тестирования проверяют ограничения на частично построенной сети. Если никакие ограничения не найдены, то используемое при этом грамматическое правило отвергается и парсер проверяет другую возможность. Это самый распространенный подход.
Синтаксический анализатор с использованием семантики. Синтаксический анализатор с использованием семантики оперирует также как и парсер, в основе которого лежит синтаксис. Однако он оперирует не с синтаксическими категориями типа группа подлежащего и группа сказуемого, а с концептами высокого уровня типа КОРАБЛЬ и ПЕРЕВОЗИТЬ.
Концептуальный парсинг. Семантическая сеть предсказывает возможные ограничения, которые могут встретиться в отношениях между словами, а также прогнозировать слова, которые позже могут встретиться в предложении. Например, глагол "давать" требует одушевленного агента и также прогнозирует возможность получателя и объекта, который будет дан. Шенк был одним из самых активных сторонников концептуального парсинга.
Парсинг, основанный на экспертизе слов. Вследствие существования большого количества неправильных образований в естественном языке многие люди вместо того, чтобы обращаться к каким-либо универсальным обобщениям, используют специальные словари, представляющие собой совокупность некоторых независимых процедур, которые называются экспертами слов. Анализ предложения рассматривается как процесс, осуществляемый совместно различными словарными экспертами. Главным сторонником этого подхода был Смол.
Аргументы за и против различных техник парсинга часто опираются не на конкретные данные, а больше на уже устоявшиеся мнения. И лишь один проект на практике сравнил несколько видов парсинга - это Язык Семантических Репрезентаций, проект разработанный в Университете Берлина. В течение нескольких лет они создали четыре разных вида парсеров для анализа немецкого языка и его записи на Язык Семантических Репрезентаций, который представляет собой сеть.
Первым парсером был парсер, созданный по подобию концептуального парсера Шенка. Было отмечено, что хотя добавление в его лексикон новых слов было довольно легко, анализ однако мог проводиться только на простых предложениях и только относительных придаточных. Расширить область синтаксической обработки этого парсера оказалось сложной задачей.
Вторым парсером были семантически ориентированные расширенные сети перехода. В этом парсере было легче обобщить синтаксис, однако аппарат синтаксиса работал медленнее, чем у первого рассмотренного парсера. Затем работа велась с парсером словарных экспертов. Здесь легко велась обработка особых случаев, однако разбросанность грамматики между отдельными составляющими делала практически невозможным ее общее понимание, поддержку и модифицирование.
Парсер, который был создан относительно недавно, - это синтаксически ориентированный парсер, основанный на общей грамматике фразовой структуры. Он наиболее систематичен, обобщен и относительно быстр.
Такие результаты в принципе соответствуют мнению других лингвистов: синтаксически ориентированные парсеры наиболее целостны, однако для них необходим определенный набор сетевых операторов для плавного взаимодействия между грамматикой и семантическими сетями.
Порождение языка по семантической сети представляет собой обратный парсинг. Вместо синтаксического анализа некоторой цепочки с целью порождения сети генератор языка производит парсинг сети для получения некоторой цепочки. Существует два варианта порождения языка из семантической сети. Первый - генератор языка просто следует по сети, превращая концепты в слова, а отношения, указанные рядом с дугами, в отношения естественного языка. Этот метод имеет много ограничений. Второй - подходы, ориентированные на синтаксис, контролируют порождение языка с помощью грамматических правил, которые используют сеть для того, чтобы определить, какое следующее правило нужно применить. Однако на практике оба метода имеют много сходств: например, первый способ представляет собой последовательность узлов, которые обрабатываются генератором языка, ориентированным на синтаксис.
Обучение машин
Графы и сети представляют собой простые понятия для программ, которые изучают новые структуры. Их преимущество при обучении заключается в легкости добавления и удаления, а также сравнения дуг и узлов. Упомянем программы, которые для обучения использовали семантические сети.
Винстон использовал реляционные графы для описания таких структур как арки и башни. Машине предлагались примеры верного и неверного описания этих структур, а программа создавала графы, которые указывали все необходимые условия для того, чтобы эта структура была именно аркой или башней.
Салветер использовал графы с центром в глаголе для представления падежных отношений, которые требуют различные глаголы. Его программа MORAN для каждого глагола выведет падежный фрейм, сравнивая одни и те же ситуации до и после их описания с использованием этого глагола.
Шенк разработал теорию Memory-Organization Packets для объяснения того, как люди узнают новую информацию из конкретных жизненных ситуаций. При этом MOP - это обобщенная абстрактная структура, которая не имеют отношения ни к одной конкретной ситуации в отдельности.
Применение на практике
Семантические сети могут быть записаны практически на любом языке программирования на любой машине. Самые популярные в этом отношении языки LISP и PROLOG. Однако многие версии были созданы и на FORTRANе, PASCALе, C и других языках программирования. Для хранения всех узлов и дуг необходима большая память, хотя первые системы были выполнены в 60-х годах прошлого века на машинах, которые были гораздо меньше и медленнее современных компьютеров.
Один из самых распространенных языков, разработанных для записи естественного языка в виде сетей, - это PLNLP (Programming Language for Natural Language Processing) Язык Программирования для Обработки Естественного Языка, созданный Хайдерном. Этот язык используется для работы с большими грамматиками с обширным покрытием. PLNLP работает с двумя видами правил: первые - с помощью правил декодирования производится синтаксический анализ линейной языковой цепочки и строится сеть; вторые - с помощью правил кодирования сканируется сеть, порождается языковая цепочка или другая трансформированная сеть.
Помимо специальных языков для семантических сетей было также разработано специальное аппаратное обеспечение. На обычных компьютерах могут быть успешно выполнены операции с языками синтаксического анализа и операции сканирования сетей. Однако для больших баз знаний нахождение нужных правил или доступ к предзнаниям может потребовать очень много времени. Чтобы позволить различным процессам поиска проходить одновременно, Фальман разработал систему NETL, которая представляет собой семантическую сеть, которая может использоваться с параллельным аппаратным обеспечением. Таким образом он хотел создать модель человеческого мозга, в котором сигналы могут двигаться по различным каналам одновременно. Другие ученые разработали параллельное программное обеспечение для поиска наиболее вероятной интерпретации двусмысленных фраз естественного языка.
Знайкина копилка, 2 февраля 2005 года