Разделы
Счетчики
Глава 2. Методика построения ЕЯ-интерфейсов к структурированным источникам данныхЕстественно-языковые интерфейсы к структурированным источникам данных
- 2.1 Основные принципы
- 2.1.1 Построение ЕЯИ как непрекращающийся итерационный процесс
- 2.1.2 Выделение настройщика как необходимого участника процесса создания ЕЯИ
- 2.1.3 Семантически-ориентированный подход как основа данной методики
- 2.1.4 Портируемость ЕЯ-интерфейса на различные среды исполнения
- 2.2 Этапы создания ЕЯ-интерфейса
- 2.2.1 Блок-схема создания ЕЯИ
- 2.2.2 Построение МБД
- 2.2.3 Построение МПО
- 2.2.4 Начальное наполнение словаря
- 2.2.5 Прокачка полей базы данных
- 2.2.6 Добавление в словарь неизвестных слов из запроса
- 2.2.7 Редактирование словаря
- 2.2.8 Тестирование ЕЯ-интерфейса и редактирование списка ЕЯ-запросов
- 2.2.9 Отладка продукционной программы
- 2.3 Общая диаграмма построения ЕЯ-интерфейса
2.1 Основные принципы
2.1.1 Построение ЕЯИ как непрекращающийся итерационный процессПроцесс построения ЕЯ-интерфейса по разработанной методике является прежде всего итерационным процессом. Характерно, что собственно эксплуатация ЕЯ-интерфейса является необходимым этапом данного процесса. поскольку настройка интерфейса к реальной базе данных в принципе не заканчивающийся процесс. Причина этого в том, что содержимое реальной базы данных, как правило, меняется со временем вследствие изменения, добавления или удаления записей. Также возможно изменение структуры базы данных, особенно в таких динамических источниках, как корпоративные базы данных, Web-сайты и хранилища - например, при появлении нового раздела сайта или при добавлении новой таблицы в реляционную базу.
Еще одна причина постоянства изменений ЕЯ-интерфейса - меняющиеся потребности в получении информации на естественном языке. Эта причина имеет влияние, очевидно, при достаточном наборе средств по изменению ЕЯ-интерфейса при появлении новых потребностей. Например, при появлении потребности задавать запросы по теме, по некоторым причинам не присутствовавшей до того в ЕЯ-интерфейсе, необходимо перестроить весь ЕЯИ: весьма вероятно изменение модели (схемы) СИД, добавлением не включенных ранее в интерфейс, но присутствовавших в СИД структурных элементов (таблиц, ресурсов, атрибутов).
И третьей причиной можно назвать сложность и несовершенство ЕЯ-интерфейса как системы. Поскольку проблема понимания ЕЯ все еще не имеет удовлетворительного решения в силу своей сложности, при создании ЕЯ-интерфейсов приходится прибегать к методам, являющимся упрощенными по сравнению с предположительно используемыми человеком при понимании языка. Такие методы могут покрывать большинство наиболее используемых типов ЕЯ-запросов, однако, как показывает опыт, существуют проблемы, как лингвистического, так и концептуального плана (Androutsopoulos et al 1995). Для временного решения этих проблем возможна перекомбинация использования механизмов анализа в ЕЯИ, а это означает изменение в ЕЯ-интерфейсе.
2.1.2 Выделение настройщика как необходимого участника процесса создания ЕЯИ
В данной методике подразумевается, что создатель и конечный пользователь - разные функциональные роли по отношению к ЕЯ-интерфейсу. Конечный пользователь должен обладать лишь необходимыми общими сведениями о предметной области интерфейса. Эти сведения обычно несложно описать несколькими фразами для предметной области средней сложности, доступно описав сущности и связи между ними на естественном языке.
Разумеется, настройщик ЕЯ-интерфейса должен обладать гораздо большими навыками, нежели конечный пользователь. В эти навыки в общем случае входят:
- Знание структуры СИД
- Знание предметной области
- Владение методологией описания ПО в формальной нотации
Не случайно в список навыков не попали лингвистические навыки. В описываемой методике единственная функция, связанная с лингвистическими навыками, заключена в этап построения МПО - функция добавления тематических словарей. Однако данная функция может быть легко автоматизирована, что и позволяет говорить об отсутствии необходимости навыков лингвиста у настройщика.
2.1.3 Семантически-ориентированный подход как основа данной методики
Основой описываемой методики построения ЕЯ-интерфейсов является предложенный в (Нариньяни 1979) семантически-ориентированный подход к анализу ЕЯ в узких предметных областях, дополненный методологией отделения предметной области от регистра ЕЯ-запросов (Sharoff, Zhigalov 1999). Этот подход развивает идею о примате семантической информации над синтаксической в автоматическом понимании ЕЯ.
Применительно к описываемой методике данный подход позволяет использовать ряд принципов:
- Абстрагирование от конкретного естественного языка
- Абстрагирование от конкретной предметной области
- Абстрагирование от конкретной базы данных
Первый пункт возможен благодаря применению в подходе правил семантического анализа, мало отличающихся от к языка к языку. Так, опыт применения этого подхода при построении ЕЯ-интерфейсов для русского, английского, немецкого, чешского и грузинского языков показал, что в этих языках основные правила анализа одни и те же, что позволяет говорить о независимости ядра системы - семантического анализатора от языка в достаточно широком диапазоне языков. В том случае, если требуется добавить поддержку какого-либо языка с большим количеством грамматических особенностей, эти особенности можно добавить добавлением в систему анализа соответствующих правил, не меняющих систему в целом. Механизмом, способствующим усилению данного принципа, является применение концептуальных структур, которые являются в высокой степени независимыми от языка, и позволяют при невозможности изменения продукционной программы повысить надежность анализа ЕЯ-запросов для любого языка.
Данная методика инвариантна также по отношению к предметной области. Поскольку основной процесс анализа работает с семантическими компонентами, выражающими семантику лексем не в предметной области, а в регистре, состав и количество классов в МПО никак не отражается на принципах анализа. Более того, применение механизма объектно-ориентированных семантических сетей позволило достаточно просто комбинировать использование структуры рабочей сети анализа и сети предметной области, поскольку и та, и другая строятся из одного и того же набора семантических компонентов, которые представлены классами узлов. Добавление же возможности использования предопределенных элементов МПО (классов, отношений) усиливает этот принцип тем, что надежность анализа повышается, если предметную область строить с применением таких известных системе анализа универсальных классов, как "Именованный объект", "Человек", а также отношений "Часть - целое", "Тип" и т.д.
Введение промежуточного уровня представления предметной области позволило скрыть детали организации базы данных в ее модели, не поднимая их на более высокий уровень. Это, в свою очередь, создает предпосылки для более эффективной работы настройщика - нет необходимости работать со схемой базы данных постоянно, ее заменяет МПО. Кроме того, при тех изменениях в структуре СИД, которые не влияют на МПО, изменения в интерфейсе минимальны, поскольку не касаются словаря.
2.1.4 Портируемость ЕЯ-интерфейса на различные среды исполнения
Применение в данной методике инструмента SNOOP позволяет говорить о независимости от платформы исполнения. Продукционная программа компилируется в байт-код, который затем интерпретируется виртуальной машиной SNOOP. Такой вариант позволяет делать для различных платформ достаточно компактные компоненты исполнения ЕЯ-интерфейсов. Причем сам ЕЯ-интерфейс является также весьма компактным блоком данных.
Данный принцип портируемости - "написано один раз - исполняется повсюду" отлично зарекомендовал себя в языке Java, который к настоящему времени стал одним из основных языков прикладной разработки. Написание же компонента исполнения ЕЯИ (то есть виртуальной машины SNOOP) на Java позволит использовать его на любой платформе, для которой существует Java-VM. Таким образом, перенос ЕЯИ на другую платформу может осуществляться практически с нулевыми усилиями. Актуальность такой возможности трудно переоценить в современном Интернет с изобилием различных платформ от мощных корпоративных серверов до мобильных устройств.
2.2 Этапы создания ЕЯ-интерфейса
Процесс создания ЕЯ-интерфейса изображен на Рис. 2.2.1-1. Пунктиром выделены шаги, которые являются штатными при эксплуатации ЕЯИ, и которые не приводят к существенной перестройке интерфейса.
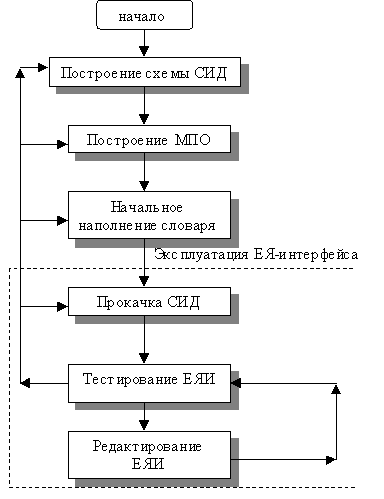
Рис. 2.2.1-1 Блок-схема процесса построения ЕЯ-интерфейса
Далее рассмотрены отдельные этапы создания и настройки ЕЯИ.
Построение модели базы данных - начальный этап настройки (Рис. 2.2.2-1). Первый шаг этого этапа заключается в выборе базы данных из списка зарегистрированных на машине. Второй шаг построения МБД настройщик выбирает те таблицы БД, которые будут входить в ЕЯ-интерфейс. На третьем шаге задаются связи между таблицами. В результате строится реляционная модель базы данных. Эта модель включает в себя список таблиц, список полей с указанием их типа для каждой таблицы, список связей между таблицами. Связь между двумя таблицами задается выражением, в которое входят поля связываемых таблиц.
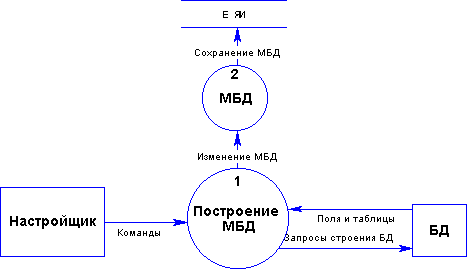
Рис. 2.2.2-1 Построение модели базы данных
Создание модели предметной области заключается в построении диаграммы классов (сущностей), и, опционально, наполнении хранилища семантических компонентов, а также построении схем концептуализаций (Рис. 2.2.3-1). Схема классов МПО изначально может строиться по реляционной схеме БД. В самом простом случае таблица соответствует классу, поле-атрибуту. После того, как подобная заготовка МПО построена, настройщик может изменять схему, добавляя, изменяя и удаляя классы, и строя связи между ними (добавлением объектных атрибутов).
В системе предусмотрена возможность добавления классов предметной области из внешней библиотеки. Более подробно данный шаг описан в главе 4.
Помимо схемы классов, МПО может дополняться хранилищем компонентов. Каждый компонент в хранилище задается фрагментом семантической сети, представляющим часть Q-запроса. Такими компонентами могут быть предикаты, множества, гиперзначения. Хранилище компонентов тесно связано со словарем - слова имеют классы компонентов, которые находятся в хранилище, и семантические ориентации, указывающие на эти компоненты.
Концептуализации строятся поверх схемы классов МПО, для каждой концептуализации задается список ролей. Каждая роль имеет семантическую ориентацию, т.е. ссылку на элемент МПО - класс, атрибут или тип.
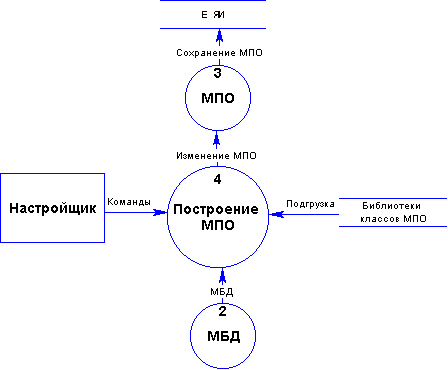
Рис. 2.2.3-1 Построение модели предметной области
2.2.4 Начальное наполнение словаря
Содержимое словаря состоит из трех основных частей: универсальная часть, лексика из базы данных и слова, введенные настройщиками. Универсальная часть появляется в словаре при создании ЕЯ-интерфейса, при этом возможен выбор универсального словаря из нескольких. Это может использоваться при построении ЕЯ-интерфейсов на определенном языке, либо по определенной тематике. Также возможна подгрузка тематического словаря (т.н. тезауруса) после начального наполнения словаря (Рис. 2.2.4-1).
Информация о наличии или необходимости тематического словаря хранится в библиотеках классов МПО. Такое решение обусловлено тесной связью словаря и МПО. Действительно, если МПО будет содержать классы, не имеющие следа в словаре, то есть словарных статей с ориентациями на эти классы, то наличие этих классов будет в лучшем случае бесполезным, а в худшем - будет мешать процессу анализа.
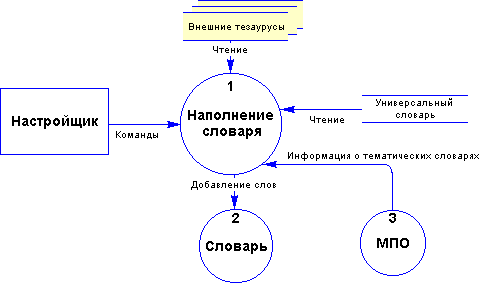
Рис. 2.2.4-1 Начальное наполнение словаря
2.2.5 Прокачка полей базы данных
Этот процесс заключается в наполнении словаря лексикой из полей базы данных (Рис. 2.2.5-1). Выкачиваются только текстовые поля, помеченные пользователем как прокачиваемые. Периодичность прокачки задается в настройках. Возможна прокачка при каждом старте системы либо по команде пользователя.
Для числовых полей есть возможность сканировать интервалы их значений в базе данных. Эти интервалы являются частями МБД, и становятся частью МПО при ее построении на основе МБД. Сканирование интервалов осуществляется вместе с прокачкой текстовых полей.
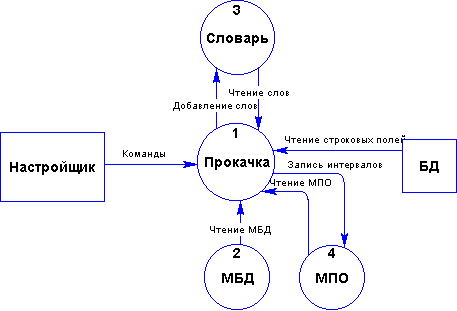
Рис. 2.2.5-1Прокачка базы данных
2.2.6 Добавление в словарь неизвестных слов из запроса
При вводе запроса, содержащего слова, отсутствующие в словаре, и не подходящие ни под один шаблон, эти слова могут выводиться пользователю в виде списка, с тем, чтобы тот мог занести их в словарь либо исправить (Рис. 2.2.6-1). Поскольку детектирование неизвестных слов проходит в основном процессе анализа, запрос может быть понят системой даже в том случае, если некоторые слова системе неизвестны.
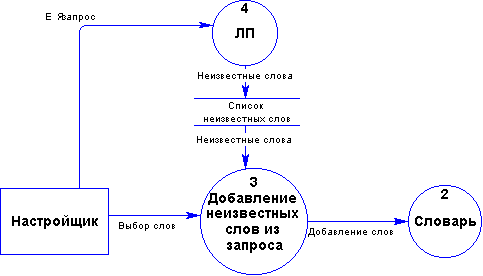
Рис. 2.2.6-1 Добавление неизвестных слов из запроса
Работа настройщика интерфейса со словарем заключается в добавлении, редактировании, поиске и удалении словарных статей. Словарными статьями, кроме слов, являются также шаблоны и словокомплексы.
2.2.8 Тестирование ЕЯ-интерфейса и редактирование списка ЕЯ-запросов
После того, как словарь наполнен универсальной составляющей и лексикой из БД, построены МБД и МПО, можно приступать к тестированию созданного ЕЯ-интерфейса. Для этого системой поддерживается ввод списка типовых ЕЯ-запросов, с возможностью его редактирования. Этот список обычно отражает потребности создаваемого ЕЯ-интерфейса. Каждый запрос из списка может быть исполнен как в окне запроса-ответа, так и в окне отладчика продукционной программы. В результате тестирования настройщик пополняет словарь лексикой ЕЯ-запросов, задавая словарным статьям семантические классы и устанавливая значения их атрибутов.
2.2.9 Отладка продукционной программы
Л-процессор, лежащий в основе описываемой системы, используется вместе со средствами отладки и редактирования продукционной программы. Это позволяет отлаживать программу анализа ЕЯ, не выходя из системы, используя все ее компоненты настройки. В компоненты отладки входят компилятор с продукционного языка SNOOP в байт-код виртуальной машины, текстовый редактор продукционной программы с возможностью отладки. При отладке возможен пошаговый режим, а также возможна установка точек останова программы. При остановке программы, а также при ее завершении в окне отладки показывается состояние семантической сети, с возможностью просмотра значений полей произвольного узла сети.
Отладка продукционной программы является необязательным шагом, и используется главным образом для тестирования самой системы построения ЕЯ-интерфейсов.
2.3 Общая диаграмма построения ЕЯ-интерфейса
На рис. 2.3-1 показана общая схема построения ЕЯ-интерфейса в DFD-нотации. ЕЯ-интерфейс является компактным образованием, включающим в себя помимо структур и данных, еще и продукционную программу.
Все операции по построению ЕЯ-интерфейса делаются в интегрированной среде. Эта среда предоставляет пользовательский сервис по созданию, изменению и тестированию ЕЯИ.
Помимо уже рассмотренных, на схеме изображен также управляющий процесс, который задает очередность исполнения остальных процессов, процесс соответствует этапу настройки. Внешними сущностями по отношению к среде и ЕЯ-интерфейсу выступает настройщик и база данных. Библиотеки ПО и универсального словаря являются внешними хранилищами.
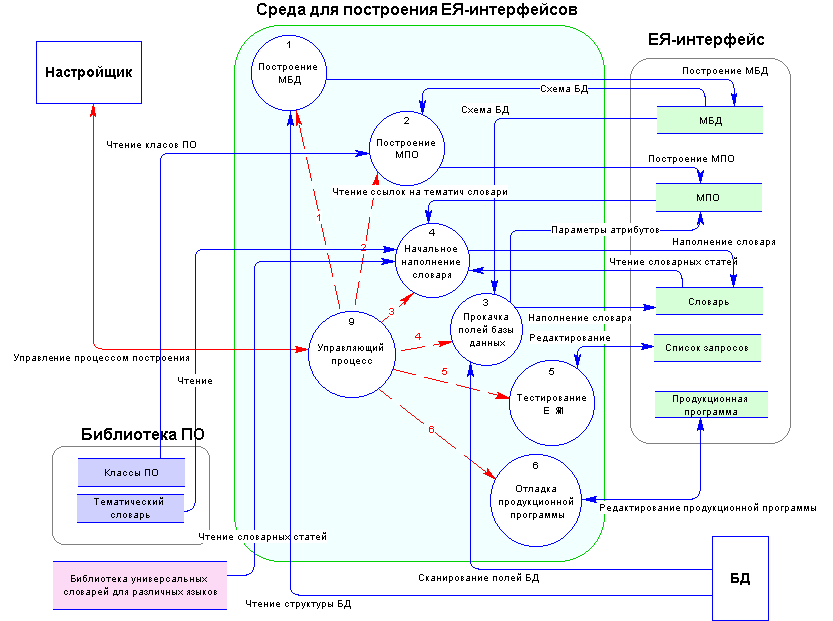
Рис. 2.3-1 Общая схема построения ЕЯ-интерфейса
Источник: (Компьютерный диалог)
Дополнительно
Дисертация Владислава Жигалова
http://www.aha.ru/~zhigalov/science/disser.zip - Word'97 (zip - 336k)